🟦آموزش مدلهای هوش مصنوعی (AI) با وجود پیشرفتهای چشمگیر، با چالشها و مشکلات متعددی روبهروست.
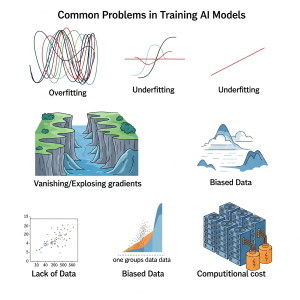
🟦 یکی از مهمترین مشکلات، کیفیت و کمیت دادههاست؛ مدلهای AI برای یادگیری نیازمند دادههای متنوع، دقیق و بدون سوگیری هستند، اما اغلب دادههای در دسترس ناقص یا آلوده به خطا هستند.
🟦مشکل دوم، بیشبرازش (Overfitting) است که در آن مدل به جای یادگیری الگوهای کلی، جزئیات خاص دادههای آموزشی را حفظ میکند و در نتیجه در دنیای واقعی عملکرد ضعیفی دارد.
🟦سومین چالش، نیاز به منابع محاسباتی بالا است؛ آموزش مدلهای بزرگ مانند شبکههای عصبی عمیق، نیازمند پردازندههای قدرتمند و کارتهای گرافیکی گرانقیمت است.
🟦همچنین، زمانبر بودن فرآیند آموزش باعث کندی توسعه میشود. چهارمین مشکل، تفسیرپذیری پایین مدلهاست؛ بسیاری از الگوریتمها مانند یادگیری عمیق به عنوان “جعبه سیاه” عمل میکنند و فهم تصمیمات آنها دشوار است.
🟦از دیگر چالشها میتوان به عدم تعمیمپذیری اشاره کرد؛ مدلها در شرایط جدید و خارج از دادههای آموزشی عملکرد خوبی ندارند.
🟦سوگیری در دادهها و الگوریتمها نیز باعث بروز نتایج ناعادلانه میشود. همچنین، تنظیم پارامترهای مدل و انتخاب بهینهی معماری شبکه نیازمند تجربه و آزمونوخطای فراوان است.
🟦 در نهایت، نبود استانداردهای مشخص در آموزش مدلها میتواند باعث ناسازگاری در کاربردهای مختلف شود.